Today we merged a pretty nice performance improvement to ZML.
PR #416 switches zml.tokenizer.Tokenizer from using the Hugging Face
tokenizers crate to using the IREE project tokenizer
when using Hugging Face tokenizer.json files.
The (upcoming) problem
Tokenizers performance is often overlooked, but it can have a significant impact on the overall latency of LLM inference.
In some cases, it can even become the bottleneck of the entire system. This is particularly important as context are
becoming bigger and bigger. For code generation, a 1M context window is regular. But a 1M context means 4MB of data (u32).
A bad (de)tokenization strategy can severely impact the overall latency of the system, and as such, it’s crucial to have a fast and efficient tokenizer.
ZML Tokenizers
ZML handles 2 types of tokenizers: Hugging Face tokenizer.json files and SentencePiece models. This is exposed
through the zml.tokenizer.Tokenizer union type, which makes this transparent to the user:
var tokenizer: zml.tokenizer.Tokenizer = try .fromFile(allocator, io, "tokenizer.json");
defer tokenizer.deinit();
const token_id = tokenizer.tokenId("<|im_start|>") orelse return error.TokenNotFound;
The zml.tokenizer.Tokenizer types also support the Encoder and Decoder types for streaming purposes.
We are also iterating on a std.Io.Reader/Writer based APIs for great composability.
For SentencePiece, we use the official google/sentencepiece implementation.
For Hugging Face, we leverage the tokenizers crate via a C trampoline.
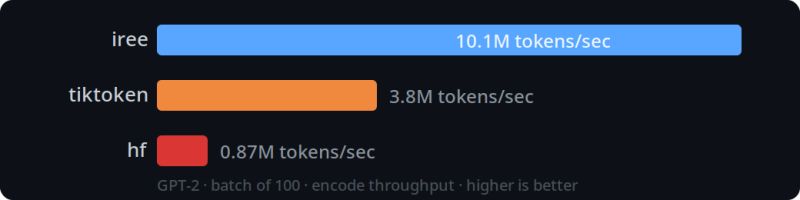
The IREE tokenizer
The IREE tokenizer, introduced by Stella Laurenzo in her LinkedIn post is a C reimplementation of the Hugging Face and TikToken tokenizers. The interesting part is that it was generated by agents, orchestrated and reviewed by Ben Vanik.
It also happens to be 10x faster than everything else.
We’re sold.
Easily integrated via Bazel
At its core, the IREE tokenizer is a pretty straightforward C API. Simple right? Well, as always, there are
strings attached. However, because ZML and IREE are built with Bazel, and thanks to our native translate-c support
in rules_zig, integration
was super easy.
IREE being a pretty big project. We had to be careful to only pull in the tokenizer and its dependencies. This is done via a git sparse checkout and a little patch to shim or remove a few graph dependencies. No biggie.
After that, we just had to depend on a few targets, bind it to our abstractions and we were good to go.
Benchmarks
With all said and done, here are the benchmarks when integrated in ZML with a ~100k tokens text:
| Model | Hugging Face (ms) | IREE oneshot / stream (ms) | Speedup |
|---|---|---|---|
| liquidai/LFM2.5-1.2B-Instruct | 40.5 | 8.5 / 7.3 | 4.8x / 5.5x |
| Qwen/Qwen3.5-9B | 59.4 | 6.0 / 8.2 | 9.9x / 7.2x |
| mistralai/Ministral-3-3B-Reasoning-2512 | 59.2 | 7.4 / 6.9 | 8x / 8.6x |
Sunsetting the Rust implementation
We’re pretty happy with the IREE tokenizer. It has been a long discussion at ZML on wether we should rewrite our own implementation in Zig, mostly because we had some ideas to optimize the tokenization process. That said, the performance uplift is so significant that we don’t think it’s worth it for now.
As such, we’ll be removing the Rust implementation and it will be done in a separate PR.
Happy hacking!